Degraded performance
Postmortem
Summary
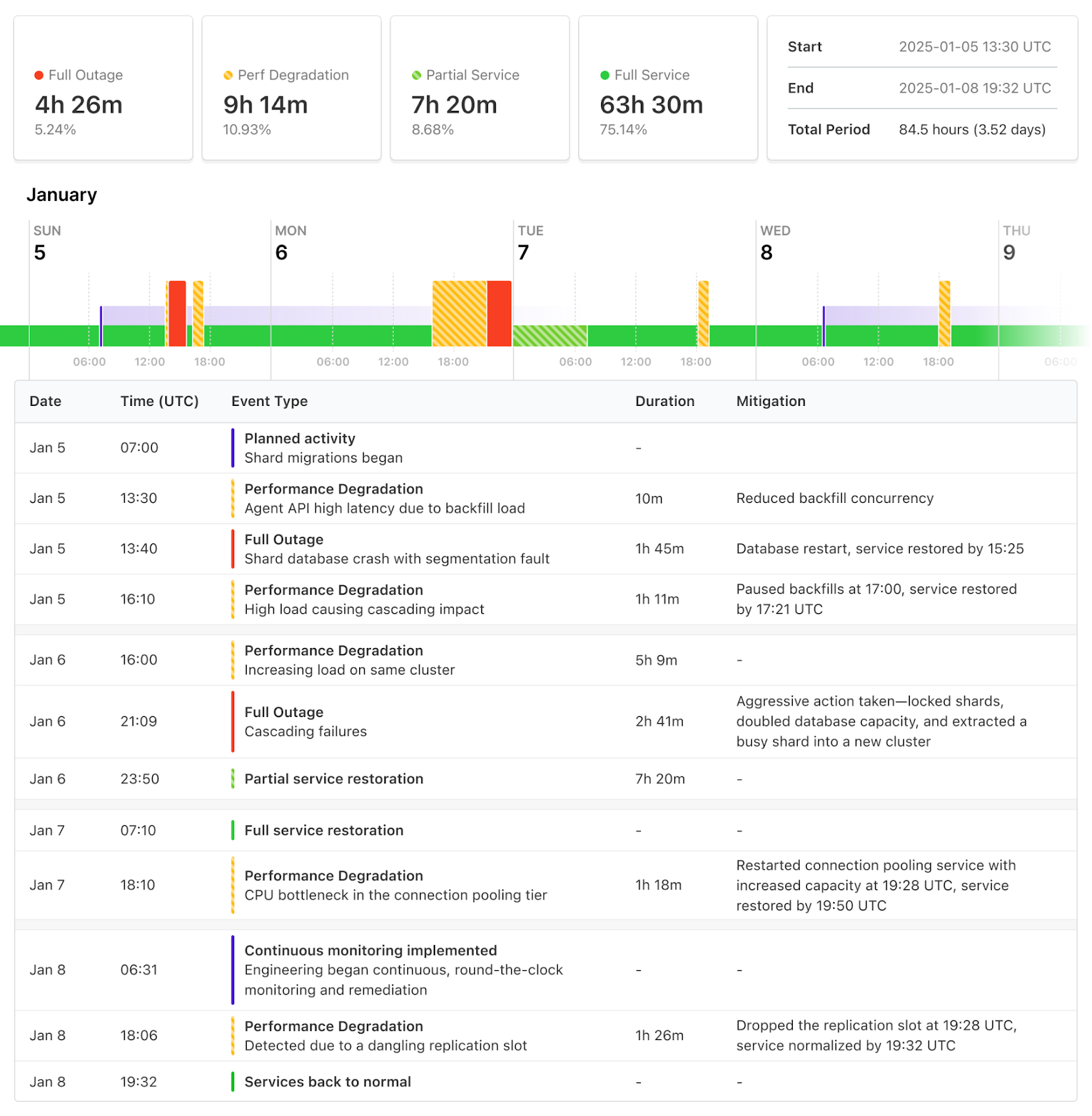
Between 2025-01-05 13:30 UTC and 2025-01-08 19:30 UTC, Buildkite Pipelines experienced four periods of degraded performance, three of which resulted in outages. The impact varied across customer workloads, primarily affecting the Buildkite Pipelines Agent API and preventing jobs from running to completion.
These outages were not caused by any single shard migration but rather by a specific pattern of load that emerged after several migrations from the higher-capacity original database to the newer, targeted database shards, combined with the surge in activity as many organizations returned to work, weeks after the relevant database shard migrations had completed. Each performance issue required specific remediation, revealing new bottlenecks under load.
As a result of these issues, we have made several changes. First, extensive mitigations were applied throughout to ensure that customer workloads don’t cause degraded performance and outages; these mitigations are proving to be effective. Second, we've significantly increased capacity across several critical bottlenecks, improving the performance and resiliency of key transactions. Finally, we’ve implemented and tested new controls for load shedding and isolating impact between customer workloads.
We recognize the seriousness and impact of this series of outages, and we deeply apologize for the disruption caused. As with any service interruption, resolving this issue was our top priority. Keith Pitt, our technical founding CEO, the leadership team, and our engineering team were deployed to identify and resolve the problems.
Timeline
Background
Buildkite has grown significantly and over the last two years, we have been working to increase the capacity and reliability of Buildkite Pipelines. Our original database was reaching the maximum capacity supported by our cloud provider, and so we introduced horizontal sharding. In Q1 2023, core database tables were extracted from our monolithic database. In Q2 and Q3 2023, horizontal sharding was implemented. We now operate 19 shards across 7 databases.
In early 2024, we successfully migrated our largest customers off this original database, which reduced load on that database by over 50%. In late 2024, we began the process of migrating all customers remaining on this original shard with customer chosen migration slots running from 2024-12-15 to the final slot currently available on 2025-03-02.
Migrations started
On Sunday 2025-01-05, the latest batch of shard migrations began as expected at 07:00 UTC. The initial phase of a migration is to lock each customer workload, move the core models and recent history to the new shard, then unlock it. This first phase finished successfully at 08:00 UTC and those customers began operating successfully from their new shard. The next phase was to backfill historical records. This second phase began as expected.
Migrations cause performance degradation leading to outage
On Sunday 2025-01-05 at 13:30 UTC performance started degrading on the Agent API leading to high request latency. We were alerted that latency was becoming unacceptable at 13:45 UTC. Investigation revealed that the migration backfill was causing higher load on the target shard than any previous migration. This high load on one shard subsequently cascaded into connection exhaustion in our database pooling tier and thread pool exhaustion in our Agent API’s application tier, the latter of which led to impact across all shards. We reduced the concurrency of the backfill to reduce load and restore performance.
At 14:24 UTC, the underlying database for the target shard experienced a segmentation fault and restarted. This caused a total outage for the affected shard, and some operations that cross shards may have had errors depending on whether they reached the affected shard. We are still actively investigating this segfault with our cloud provider. Once the database returned, it returned healthy, and service was restored by 15:25 UTC. We continued monitoring.
At 16:10 UTC we observed high load again. The same cascading behaviour eventually caused global impact, leading to outage for all customers. We entirely paused the backfills at 17:00 UTC to restore service by 17:21 UTC.
Remaining backfills have since been resumed at lower concurrency and monitored through to completion without impact. The backfill process has also been adjusted to respect database load as backpressure, to ensure backfills will never overwhelm a database under load.
Performance degradation, leading to outage
On Monday 2025-01-06 at 16:00 UTC, we started experiencing high load which turned into performance degradation causing an alert at 16:37 UTC. The same underlying database cluster seemed to be a bottleneck.
Between 16:37 and 23:00 UTC engineers worked to identify troublesome workloads and implement load shedding to restore service. It was not clear that the migrations were a root cause at this time. The workloads driving the load appeared to be on a different shard. But the same cascading effects were observed with slowly increasing impact. At 21:09 UTC the cascading effects resulted in a service outage.
Capacity increased, service restored
At 23:00 UTC a decision was made to take more drastic action. The shards driving load were entirely locked, and customers on these shards experienced total outage. The underlying database was upgraded to double its size. And one of the busiest shards on that database was extracted into its own new database cluster. By 2025-01-07 01:05 UTC we were seeing partial restoration, progressively restoring access by customer. By 07:10 UTC service was fully restored.
Our problematic database cluster now had twice the capacity for 3/4 shards.
Performance degradation, leading to outage
On Wednesday 2025-01-07 at 18:10 UTC, we once again started experiencing performance degradation. Investigation revealed that database load was nominal but there was a CPU utilization plateau in the database connection pooling tier. This bottleneck led to degraded performance for all customers eventually leading to high error rates and outage.
Capacity increased, service restored
At 19:28 UTC the database connection pooling service was restarted with greater capacity. Once available, restored workloads again caused high load on the database cluster causing performance degradation which led to an outage. Load shedding restored degraded performance, yielding in service restoration by 19:50 UTC.
We also found that the database struggling with load was seeing 3-4x more load than any other database at peak load. This clue led us to finding that the database connection pooling layer was limiting connections to the database per shard instead of per cluster, but connections are a cluster wide resource. We know that our databases are healthy at a certain level of concurrency but start thrashing when given too many active connections simultaneously.
Our current database connection pooling architecture makes it difficult for us to implement these concurrency limits at the cluster level. But the additional capacity added to the problematic database cluster combined with extracting one shard into an additional cluster has given us enough capacity to handle peak load during regular operations while we work on improving our database connection pooling architecture to add concurrency constraints.
On Wednesday, 2025-01-08 06:31 UTC our engineering team began constant, round the clock shifts to minimise customer impact, actively monitor, and be ready to remediate.
Performance degradation
On Wednesday, 2025-01-08 at 18:06 UTC we observed performance degradation due to the same database. Measures put in place to isolate the impact from that database across the service combined with load shedding efforts kept the service available. The source of the degradation is traced to a dangling replication slot left behind during the setup of the new cluster on 2025-01-06.
Replication slot cleaned up, performance restored
At 19:28 UTC the dangling replication slot was dropped. By 19:32 UTC, performance returned to normal.
Due to our haste in configuring the new database, our usual monitor for replication slot lag contained a mistake, so we were not alerted to this issue in a timely manner. This mistake has been corrected, and our usual runbooks and modules for provisioning databases do not contain this mistake.
Next Steps
Throughout the incident and in its aftermath, extensive efforts were undertaken to identify the root causes of high load and implement performance improvements. While not every investigative path directly addressed the immediate issues, many revealed previously unexposed bottlenecks within our infrastructure - areas that have not yet been stressed but could have caused future disruptions. These discoveries have been invaluable, and we are now proactively resolving these vulnerabilities to strengthen our systems and prevent similar incidents moving forward.
We have learned a great deal during this period, and while it’s not possible to capture every learning or action taken or planned in a single narrative, the following key efforts are being pursued:
Seasonal Load
Given the confidence gained by initial load testing and the migrations already performed over the past year, we wanted to allow customers to take advantage of their seasonal low periods to perform shard migrations, as a win-win. This caused us to discount the risk of performing migrations during a seasonal low period and what impacts might emerge when regular peak traffic returned.
Our usual approach to these sorts of things is to be “careful yet relentless.” We like to make small changes and incrementally roll them out, observing their behaviour and impact at peak loads. In this case we may have been overconfident, and this is a reminder to take smaller, more frequent steps and always evaluate changes under peak loads.
Database shard planning
We’ve reduced the amount of shards we allow in a database cluster. Smaller steps when changing shard distribution strategies are required to prevent unexpected impacts. Future database shard and cluster architectural changes will be made more incrementally.
Database pooling architecture
Several times when reconfiguring our databases and database connection pools we needed to deploy changes to our database connection pooling tier. These deploys took longer than expected, and often caused momentary downtime when performed at peak load. We are evolving our database connection pooling architecture so that we can make zero-downtime changes with faster feedback.
Our current architecture also doesn’t allow us to implement cluster-level connection limits. We are working on this problem so that we can introduce better bulkheading and concurrency limits to prevent overwhelming our databases at peak load in future.
Shard isolation
When introducing sharding we were able to add shard selection and routing into most functionality across Buildkite Pipelines. But some key transactions do not contain enough information to route directly to the correct shard without modification or additional functionality.
For example, new agents register with Buildkite using an agent registration token. This token does not contain any information about which organization it belongs to nor which shard it should ultimately be routed toward. To solve this we query each shard until the correct shard is determined and cache the result. While effective under normal conditions, this approach became a point of failure when a single shard experienced issues, leading to broader service disruptions.
Several opportunities to avoid cross shard queries and improve cache hit rates were revealed during the incident. Transactions are being enhanced to embed detailed routing data upfront, such as customer specific endpoints, to ensure requests are routed directly to the correct shard. Improved caching strategies are being employed to increase cache hit ratios when direct routing isn’t feasible.
Shard-aligned infrastructure
Our background worker infrastructure, which powers Buildkite Pipelines, had already been modified to leverage database sharding. Each shard operates with distinct queues and dedicated capacity. This allowed effective observation of workloads per shard and enabled key load shedding efforts. This design has been instrumental in maintaining system stability and performance over the past 6 months.
Extending shard-aligned infrastructure to all layers was already planned. During incident response we successfully deployed a shard-isolated Agent API tier to contain the impact and protect unaffected workloads. We will continue to expand this model, establishing stronger bulkheading between customer workloads across different shards.
Finally
We sincerely apologize for the disruption and inconvenience this series of outages caused. We understand how critical our services are to your operations, and we deeply regret the impact this had on your workflows. Please know that we are fully committed to learning from this incident and have taken immediate and long-term actions to strengthen our infrastructure. Thank you for your continued trust and support as we work to deliver a more resilient and reliable Buildkite experience.